
Nuevas perspectivas del software. Paradigmas reactivo y funcional
El software está cambiando. Esta es una afirmación bastante trivial, teniendo en cuenta que hablamos de un sector en constante desarrollo, con una vida corta (en relación con otras áreas del conocimiento) y con perspectivas de continuar revolucionando el mundo. Sin embargo, en el último lustro, la explosión de los volúmenes de datos y la forma de procesarlos, así como la irrupción de las tecnologías Big Data, han transformado los paradigmas de programación y diseño de infraestructuras de software dando lugar a nuevas tecnologías y nuevos paradigmas de programación.
Hace unos meses, tuvimos la oportunidad de asistir a una conferencia organizada por Lightbend, en la que se hablaba de nuevos modelos de diseño de aplicaciones con una metodología distinta a las tradicionales. En lugar de las consideraciones tradicionales de diseño (Atomicidad, Consistencia, Aislamiento y Durabilidad como estrategias de construcción) se planteaba la necesidad de responder a las nuevas necesidades de negocio a través de “Acid V2”, (Figura 1) con el fin de conseguir sistemas distribuidos que permitan la escalabilidad mediante el uso de plataformas distribuidas, y una gestión de fallos distinta a la habitual, mediante patrones de supervisión que permitan a su vez garantizar una estabilidad mayor de los sistemas.
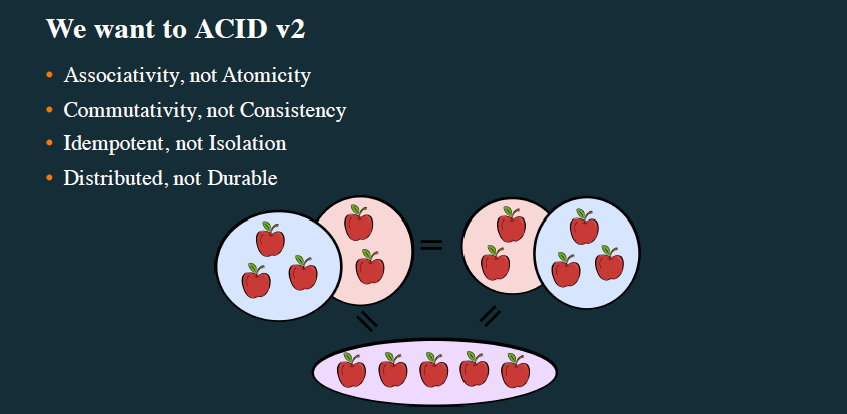
Fig1. Nuevas necesidades de diseño.
Una de las tecnologías aparecidas al calor de los nuevos diseños de arquitecturas es Akka. Akka es un framework sobre Scala basado en lo que se conoce como un sistema de actores. Akka permite crear software altamente concurrente, escalable (elastic), distribuido, flexible, tolerante a fallos (resilent) y basado en un sistema de mensajes para la JVM (Figura 2). Esta plataforma pretende ser un sistema reactivo. Esto quiere decir que está diseñado para reaccionar a eventos y escalar ante distintas cargas.
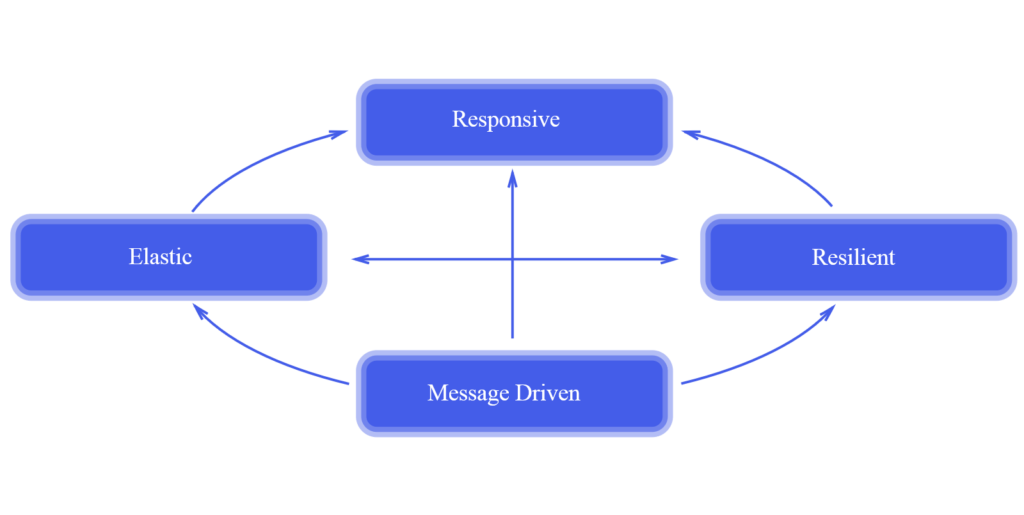
Fig2. Paradigma reactivo. Modelo Akka.
Un actor es la unidad fundamental del sistema y engloba un estado y un comportamiento.
Cada actor tiene una dirección única en el sistema y es referenciable a través de ella. Además, la única manera que tienen los actores de comunicarse entre ellos es mediante mensajes.
Por sus características, Akka está siendo utilizado en resolución de problemas relacionados con el control y procesamiento de eventos, así como en novedosas aplicaciones de microservicios ligeros. Akka también se conforma ahora mismo como el núcleo de procesamiento de numerosas aplicaciones Big Data basadas en Spark (Incluso fue el framework base de comunicaciones del propio Spark en sus orígenes).
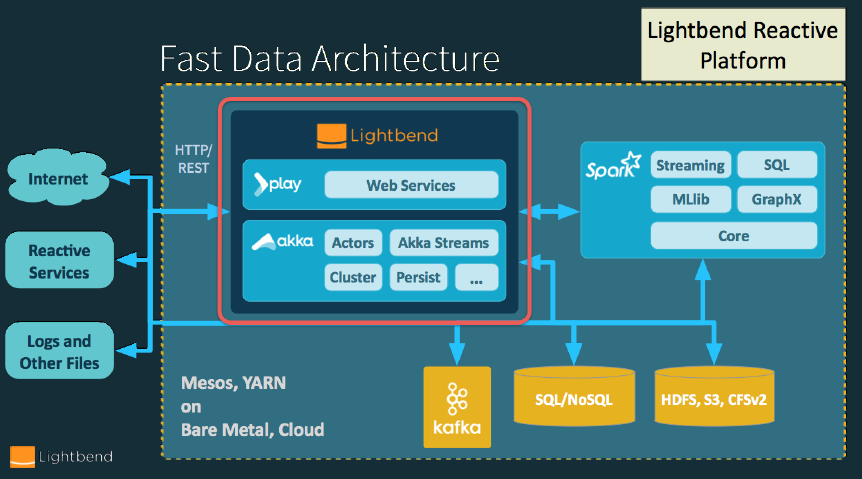
Fig3. Akka como núcleo de procesos de información en arquitecturas Big Data.
Scala es un lenguaje multiparadigma diseñado para correr sobre la JVM. Permite expresar patrones de programación funcional y programación orientada a objetos. Es rápido, elegante y fuerza a un tipado seguro. Por estas y otras razones ha sido el elegido para el API (y el código) de Akka, así como para la implementación de Spark.
El resultado final de la combinación de estas tecnologías permite aprovechar la potencia de akka como framework reactivo, optimizando los procesos internos de los actores mediante el uso de implementaciones funcionales en Scala.
Optimización combinatoria. Problema del máximo clique.
Dentro de las aplicaciones de las matemáticas a la mejora de rendimiento productivo y la optimización de las condiciones de trabajo, destaca el impacto económico que representa una solución optima de los problemas combinatorios, tanto en la mejora de la ventaja competitiva como en ahorro a largo plazo quese consigue con una inversión puntual en la mejora de los procesos.
Los ejemplos de problemas de optimización combinatoria que se presentan en la producción y la venta son abundantes, el clásico TSP para el cálculo de rutas que minimiza los gastos de transporte, los problemas de asignación de recursos y maquinaria para evitar los tiempos muertos o el ahorro de espacio mediante configuraciones de almacenamiento.
Dentro del ámbito de estos problemas, se conoce como problema del máximo clique (PMC) a la búsqueda del subgrafo de mayor tamaño en el que todos los vértices sean adyacentes, también conocido como subgrafo completo. Dicho de otra manera, el problema consiste en encontrar dentro de un grafo, el conjunto mayor de vértices en que todos sean vecinos directos de todos. (Figura 4)
Ese problema en concreto tiene multitud de aplicaciones prácticas dentro de la biología molecular y la biotecnología, la visión artificial (Segmentación de imágenes y reconocimiento de patrones), el tratamiento de datos para detección del fraude (Análisis de Link Farm) y el análisis de conducta y relaciones a través del estudio de redes sociales.
Al igual que en el resto de los problemas combinatorios, la búsqueda de la solución exacta se realiza normalmente a través de algoritmos secuenciales, y esto limita las posibilidades de escalabilidad en el volumen del problema, así como el cumplimiento de los requisitos de rendimiento que habitualmente reclaman los clientes.
La pregunta que nos planteamos entonces es: ¿Podríamos conseguir la resolución de este tipo de problemas estableciendo algún tipo de algoritmo paralelo que nos permitiera trabajar de forma distribuida?¿Podríamos apoyarnos en las nuevas tecnologías citadas para buscar una solución innovadora?
 Fig4. Clique máximo contenido en el grafo
Fig4. Clique máximo contenido en el grafo
¿Cómo planteamos el problema?
Una de las características de los problemas de optimización combinatoria, y en concreto de los problemas NP-Completos, es que resulta muy complicado aplicar la técnica “Divide y vencerás” para poder resolver el problema de forma paralela.
En el caso concreto del análisis de grafos, surge habitualmente de forma intuitiva la idea de fragmentar o partir el problema. Cabría pensar en la posibilidad de dividir el problema en cuadrantes o parcelas, para resolverlas en paralelo y acelerar así el proceso. Sin embargo, ¿cómo garantizar que la solución no está contenida entre los límites de estas parcelas? Para poder descartar esto deberíamos analizar los límites de las divisiones, y posteriormente los nuevos límites que establecimos en el segundo análisis y así sucesivamente hasta conseguir una solución incluso más lenta que la original sin dividir.
En la figura 5 aparece a la izquierda una partición en parcelas, en la que además las parcelas cortan con la solución (H-G-F-E)
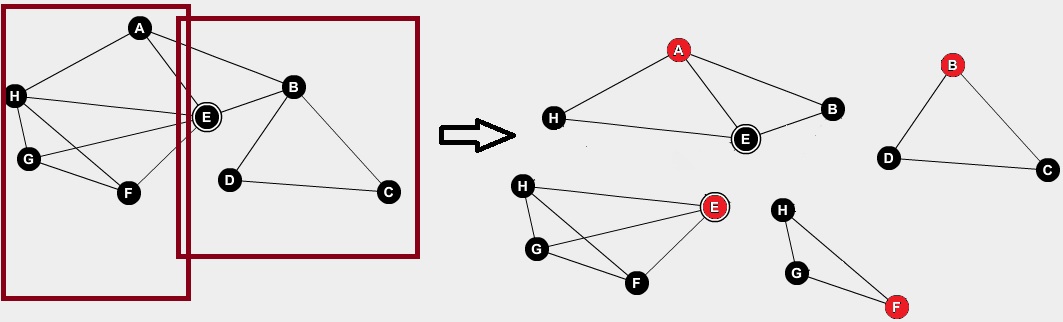
Fig5. Partición en parcelas y partición en nodos
Trabajando sobre la paralelización del problema del clique, pensamos que existía la posibilidad razonable de que, consiguiendo que cada vértice resolviera el problema para si mismo y sus vecinos superiores (tomamos aquí un nombrado y ordenación de los vértices y llamaremos subgrafo orientado de n a los que tengan un id > n y estén relacionados con él), el tiempo que tardaría en solucionar el problema entero en condiciones ideales sería igual que el tiempo del subgrafo mayor en resolverse a si mismo. De esta manera, según la figura 5 en su parte derecha, las particiones serían tantas como vértices tengan dos o más vecinos superiores.
¿Cómo resolvemos el problema?
Siguiendo el modelo de actores de Akka, definimos dos tipos de actores. En primer lugar necesitaremos un actor de control, que se encargará de gestionar los actores hijos (vértices o actores de ejecución). Será el encargado de crear y arrancar los procesos dentro de cada vértice, y recibirá las notificaciones de nivel de clique que vayan encontrando los hijos. Se encargará también de decidir cuando ha acabado el procesamiento y por tanto la ejecución.
En segundo lugar declaramos cada vértice como un actor, y lo construimos con la información de cuales son sus vértices adyacentes como atributo inmutable para respetar los patrones funcionales. Esto significa que cada actor vértice es una unidad de procesamiento autocontenida, tiene toda la información necesaria para realizar sus operaciones anónimamente y no requiere consultar otros actores para ejecutar su lógica.
Una vez montado el sistema de actores, lanzamos una señal de arranque a todos los vértices, para que cada uno envíe un mensaje al siguiente con la información de sus vecinos ordenados como candidatos y su firma. Cada actor recibe mensajes de esta manera con posibles combinaciones, y decide mediante un algoritmo branch and bound, si reenvía al siguiente vecino un espacio de intersección entre sus vecinos y lo que comparte con los que han firmado anteriormente. De esta manera, los mensajes se van rellenando con información de firmantes que pertenecen a un clique.
Cada vez que un actor completa un espacio por no poder explorar más, envía un mensaje a un actor de control, que a su vez lo reenvía en modo broadcast al resto de actores. De este modo se conoce en tiempo real el momento en el que el máximo clique aumenta, permitiendo modificar las podas del branching descartando búsquedas que tengan unas posibilidades menores que las soluciones que se van encontrando en cada momento.
Los subgrafos se exploran totalmente en paralelo con esta implementación, y los patrones reactivos se respetan bajo la premisa de que cada vértice solamente tiene un método autocontenido, no conoce información sobre otros actores y además no la requiere en ningún momento.
Finalmente con esta implementación, hemos conseguido un modelo reactivo que nos permite expandir la solución en distintas máquinas mediante el sistema de actores. El modelo es razonablemente menos rápido que las soluciones de mercado para solucionar este problema (Se parte de una limitación de comunicaciones que no existe en las soluciones lineales). Sin embargo, con esta formulación ganamos la posibilidad de resolver en infraestructuras físicas tan grandes como determinemos, (permitiendo incluso trabajar con un vértice en cada máquina si dispusiéramos de las suficientes unidades de computación) acortando así los tiempos de solución y permitiendo también la solución de problemas de un tamaño mayor aumentando los recursos.
Referencias:
Modelo de algoritmos lineales para la resolució del clique: http://www.dcs.gla.ac.uk/~pat/maxClique/distribution/TR-2012-333.pdf
Framework AKKA
Lenguaje Scala
http://www.scala-lang.org/documentation/
Algoritmo branch and bound
https://en.wikipedia.org/wiki/Branch_and_bound
Programacion reactivo funcional



