
Brais Rodríguez Suarez y José Manuel Simón Ramos
En un mundo donde los datos se han vuelto cada vez más relevantes y valiosos, su gestión y procesamiento se convierten en aspectos cruciales para extraer su máximo valor. Para lograr esto, es esencial diseñar y coordinar tres apartados principales:
- La arquitectura de los procesos que manejan los datos, donde se engloban enfoques como Data Warehouse, Data Lake o Data Lakehouse (del cual ya hablamos con más detalle en el artículo «Introducción a Data Lakehouse»).
- El método y formato en el que se almacenan.
- Consumo de los datos en informes y modelos de análisis.
En cuanto al diseño de almacenamiento de los datos existen diferentes técnicas. Un ejemplo de esto es el esquema Data Staging Area, aplicado comúnmente en los Data Warehouse. Este esquema consistente en crear un área de Staging en la que se almacenarán los datos de forma temporal e incremental antes de ser consolidados en el Data Warehouse. No obstante, este enfoque presenta el problema de que, al no almacenar una copia del dato original, se crea una dependencia con las fuentes de dato origen. Esto se debe a que estas fuentes no tienen por qué mantener siempre la información, pudiendo así perder la trazabilidad y la consistencia del dato final.
Es por ello por lo que se ha popularizado un nuevo enfoque más flexible, escalable y mantenible, conocido como arquitectura de medalla. Este planteamiento busca organizar el dato en distintas capas/etapas de forma que el dato evoluciona y se mejora según pasa por cada una de ellas. En el presente artículo se tratarán sus fundamentos básicos, características principales, y las ventajas y desventajas de su implementación.

Qué es la Arquitectura de Medalla
La arquitectura de medalla (Medallion Architecture en inglés), es un patrón de diseño de datos en el que se plantea un enfoque integral para la organización y gestión de los datos de una forma lógica dentro de un Data Lakehouse. Los principales beneficios que proporciona esta arquitectura son:
- Gestión eficiente y escalable de grandes volúmenes de datos. Facilitando el análisis avanzado y la toma de decisiones basada en datos.
- Simplificación de la lógica de transformación. Cada etapa se encarga de realizar una función concreta en el refinamiento de los datos. Esto proporciona una mayor agilidad en los equipos de trabajo, ya que el flujo de transformaciones es más comprensible.
- Evita reprocesar datos desde origen. La primera capa de la arquitectura almacena todo el histórico de los datos sin procesar. Esto hace posible reconstruir cualquier tabla en las capas posteriores sin depender del origen de datos. De este modo se evitan problemas en el caso de pérdidas de información por parte de la fuente de datos de origen.
Por el contrario, una desventaja reside en el aumento del espacio de almacenamiento. Esto se debe a que, al tener distintos estados del dato en cada una de las etapas, el espacio total de almacenamiento es superior al de una solución tradicional.
Sin embargo, el impacto real asociado a esto no es tan relevante. Por un lado, el evitar reprocesar datos desde el origen en caso de ser necesario, permite ahorrar costes asociados al cómputo. Por otra parte, el uso de formatos de almacenamiento columnares como Parquet, unido a técnicas de compresión como Snappy, reducen en gran medida el tamaño de la información almacenada, reduciendo el coste asociado al almacenamiento.
En las siguientes secciones se tratarán las diferentes etapas que conforman la arquitectura de medalla así como la lógica de transformación que se aplica en cada una.
Capa de bronze
Es la primera etapa dentro de la arquitectura. En esta capa se encuentran los datos que llegan desde el origen. Sus principales características son:
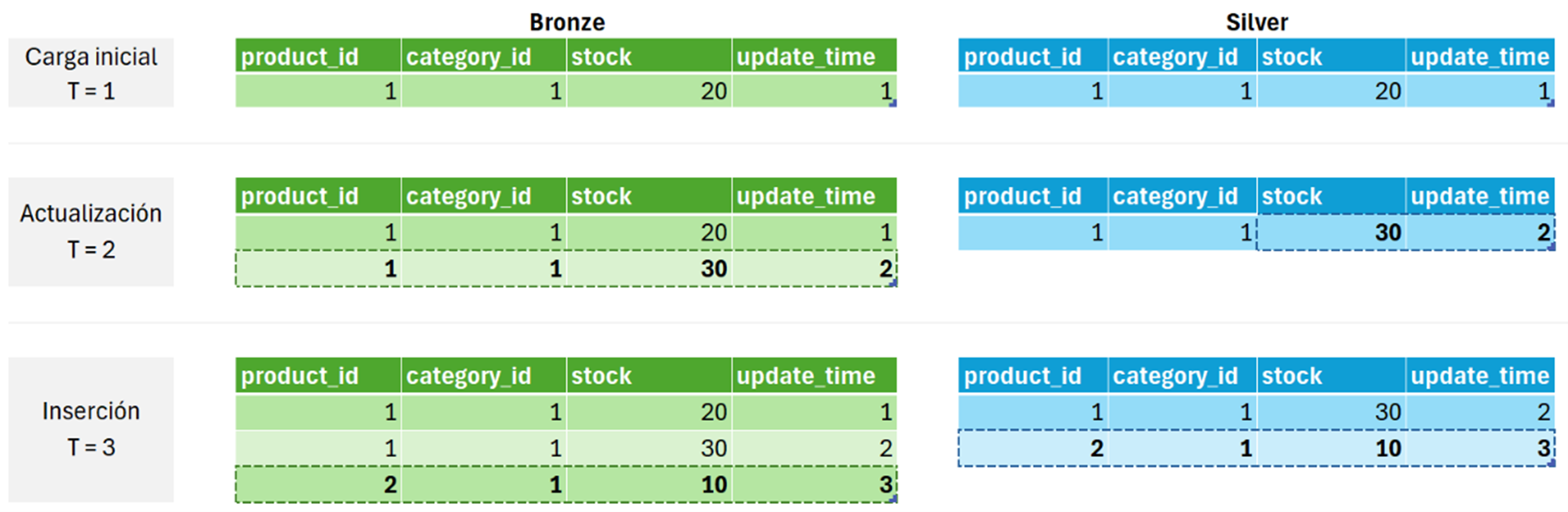
- Historificación: Se almacena el histórico de cambios de cada uno de los registros. La selección de qué valor prevalece se abordará en las etapas posteriores.
- Almacena las diferentes versiones de un dato. Esto se traduce en que en bronze no existe ningún registro duplicado. Por ejemplo, si en la carga inicial hay 100.000 registros, y se modifican 10.000, en la siguiente carga solo se añadirán los 10.000 registros alterados (en lugar de cargar nuevamente los 90.000 registros que no han cambiado).
- Evolución del esquema: Las modificaciones en los datos de origen se adaptan de forma automática en las tablas de esta capa. Estas modificaciones pueden incluir la aparición o eliminación de columnas, así como cambios en el tipo de datos (siempre que este cambio sea compatible). Cabe destacar que este proceso se realiza perder ningún dato existente en bronze.
- Incremental: Las inserciones, actualizaciones y borrados de datos en el origen se traduce en un nuevo registro de dicho evento en la tabla de bronze. Dicho de otro modo, en esta capa únicamente se añade información.
En la siguiente figura se muestra un ejemplo de cómo evolucionan los datos en la capa de bronze para distintos momentos de tiempo en función de las variaciones en los datos de origen:

Capa de silver
Representa el segundo nivel en la arquitectura de datos. Esta fase tiene como objetivo principal comparar, fusionar y limpiar los datos de la capa de bronce, generando una vista empresarial completa de cada tabla anterior. Las operaciones de limpieza y transformación llevadas a cabo en esta etapa han de ser las mínimas necesarias, además de que estas no pueden contener ningún tipo de lógica de negocio. Otras características de esta etapa son:
- Definición del tipo de datos. Se aplicarán operaciones de conversión de tipo de datos, formateos, así como modificar/estandarizar los nombres de las columnas, en caso de ser necesario.
- Selección de la mejor versión del dato. Se selecciona la versión más reciente del dato almacenada en el histórico de la capa de bronze. Dicha versión no tiene por qué ser la última cargada, si no que puede estar definida por otro tipo de lógica, por ejemplo, la fecha de última modificación.
- Limpieza del dato. En esta se pueden aplicar operaciones asociadas a la limpieza del dato, como por ejemplo filtrar filas corruptas y trasladarlas a una tabla de cuarentena para su revisión.
- Punto de partida de nuevas soluciones. Al no contener ningún tipo de lógica de negocio, los datos de esta capa pueden resultar útiles de cara a emplearlos en nuevos análisis, proyectos, etc.
Por ejemplo, suponiendo que tenemos en silver una tabla llamada “Product” con la siguiente información:

A la que se añaden dos nuevas columnas mediante la siguiente lógica:
- 1. ✅ Generar una nueva columna llamada “load_year” con la siguiente función:

En este caso, sí que sería correcto generar esta nueva columna en la etapa de silver ya que no lleva asociada ningún tipo de lógica de negocio.
- 2. ❌ Generar una nueva columna “stock_level” con la siguiente función:

En este otro caso no sería correcto generar en esta etapa la columna “stock_level” ya que los valores que tomaría esa columna para los distintos registros dependen de una lógica interna. Basándose en el esquema de medalla, la columna “stock_level” debería generarse dentro de la etapa de gold.
Capa de gold
Contiene los datos consolidados tras haber aplicado la lógica de negocio deseada. Del mismo modo, en la capa de gold se pueden generar nuevos modelos de datos específicos para cada proyecto, equipo, área o necesidad. Por ejemplo, conjuntos de datos para modelos de Machine Learning, informes de Inteligencia de Negocio, acceso a los datos por parte de terceros, minería de datos, etc. Además de esto la capa gold ofrece las siguientes características:
- Fuente única de la verdad: Al aplicar operaciones de calidad del dato, se garantiza confiabilidad y consistencia a la información almacenada en esta capa.
- Preparados para el consumo: Los datos son adaptados específicamente para satisfacer cada caso de uso concreto tanto a nivel de información (agregaciones, joins, anonimización), como a nivel de modelo de datos (estrella, copo de nieve, etc.). Esto facilita el trabajo de los usuarios finales al reducir la necesidad de hacer operaciones adicionales sobre los datos.
- Rendimiento: Permite aplicar técnicas de optimización específicas para cada tabla, reduciendo así los tiempos de consumo de la información. Por ejemplo, aplicando particionamiento, ordenando y agrupando datos relacionados dentro de un fichero, etc.
En la siguiente figura se muestra un ejemplo de cómo los datos pasan de la capa de silver a la capa de gold. En este caso la lógica de negocio consiste en aplicar una agregación para obtener la cantidad de stock disponible por categoría de producto:

Conclusiones
A lo largo del artículo se ha presentado la arquitectura de medalla, un enfoque efectivo y sencillo para gestionar y organizar los datos dentro de un Data Lakehouse, obteniendo un mayor valor de ellos. Es por esto por lo que grandes proveedores de recursos en la nube como Databricks y Microsoft recomiendan y utilizan la arquitectura de medalla en las propuestas de Data Lakehouse que ofrecen: Databricks Lakehouse y Microsoft Fabric One Lake.
Desde decide4AI apostamos por este tipo de soluciones en combinación con Data Lakehouse, desarrollando arquitecturas de bajo coste, escalables y eficientes que permitan mejorar la calidad y la gestión de los datos de las organizaciones, consiguiendo generar un mayor valor y mejorar la toma de decisiones.
Referencias
- https://learn.microsoft.com/en-us/azure/databricks/lakehouse/medallion
- https://www.databricks.com/glossary/medallion-architecture
- https://piethein.medium.com/medallion-architecture-best-practices-for-managing-bronze-silver-and-gold-486de7c90055
- https://www.advancinganalytics.co.uk/blog/medallion-architecture
- Delta Lake: The Definitive Guide Modern Data Lakehouse Architectures with Data Lakes Book
- Rise of the Data Lakehouse. Building the Data Lakehouse 2nd Edition – Bill Inmon.


