
Brais Rodríguez Suarez y José Manuel Simón Ramos
En la era digital actual, los datos se han convertido en uno de los recursos más valiosos para las organizaciones de todos los sectores. Desde empresas tecnológicas hasta instituciones financieras, la capacidad de recopilar, almacenar y analizar datos de manera efectiva es fundamental para la toma de decisiones estratégicas y la mejora continua. Sin embargo, con el crecimiento exponencial en el volumen y la complejidad de los datos generados, surge la necesidad de gestionarlos de manera eficiente para evitar que se conviertan en pantanos de datos, donde la información valiosa se pierde en amplios sistemas desorganizados, dificultando su uso y explotación.
Es en este contexto donde aparecen conceptos como Data Warehouse y Data Lake, que tradicionalmente han sido arquitecturas de referencia para la explotación de datos a gran escala. No obstante, cada uno presenta limitaciones y desafíos específicos en términos de rendimiento, escalabilidad y confiabilidad. Para solventarlas, aparece una nueva arquitectura conocida como Data Lakehouse.
En este artículo se tratarán los fundamentos básicos de la arquitectura Data Lakehouse, sus componentes principales, y el formato y esquema de almacenamiento.
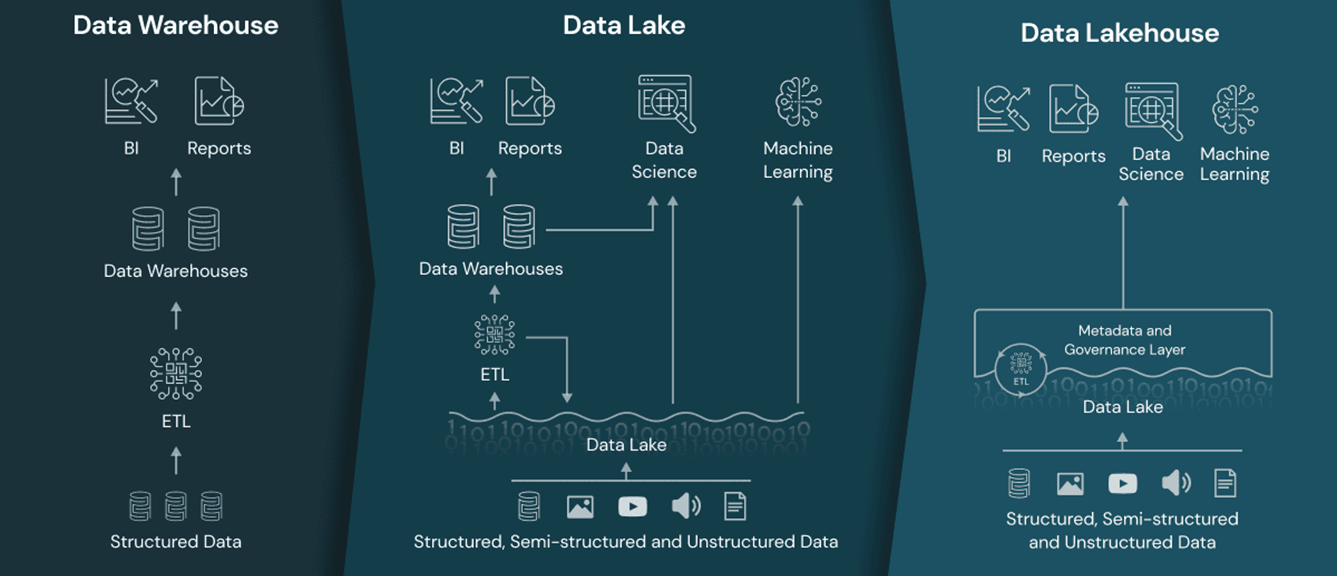
Qué es un Data Lakehouse
Un Data Lakehouse es una plataforma integral para la gestión de datos que combina la capacidad de almacenamiento de datos no estructurados y semiestructurados de un Data Lake, con la capacidad de procesamiento y análisis de un Data Warehouse. Al combinar ambas soluciones, Data Lakehouse ofrece una solución completa eficiente y confiable, sin comprometer el rendimiento o la escalabilidad.
En cuanto al despliegue de esta arquitectura, puede llevarse a cabo tanto en la nube como on-premise. No obstante, es recomendable alojarlo en la nube para aprovechar todas sus ventajas como la alta disponibilidad, el menor tiempo de implantación, simplicidad en el mantenimiento, etc.
Las principales características de un Data Lakehouse son:
- Escalabilidad y flexibilidad. Existe una división completa entre procesamiento y almacenamiento. Esto facilita la escalabilidad de cualquiera de estas partes de forma conjunta o independiente, ajustándose mejor al volumen y las necesidades de los datos.
- Capa de metadatos. Ayuda a organizar y proveer de información sobre los datos almacenados en el sistema: tipos de datos, linaje, documentación, etc.
- Gobernanza. Cuenta con un control de acceso a los datos granular limitando el acceso y acciones que un usuario puede realizar sobre estos, incrementando la seguridad y privacidad en los datos.
- Bajo coste: Los servicios utilizados siguen la filosofía de pago por uso, sin comprometerse a cuotas fijas. Del mismo modo, la independencia de sus componentes principales permite reducir el sobredimensionamiento y los costes en partes innecesarias.
- Soporta procesamiento de datos en batch y en streaming. Lo que le permite ajustarse mejor a las distintas necesidades de frecuencia de actualización de los datos (diaria, horaria, próximo al tiempo real, etc.).
- Portabilidad: Al fundamentarse en tecnologías Open Source (Python, Spark, Delta Lake, etc.) se elimina la necesidad de licencias y la dependencia a un único proveedor de servicios en la nube.
En la siguiente tabla se muestra una comparativa entre distintas funcionalidades y como estas se ajustan dentro de cada uno de los sistemas mencionados anteriormente:

Arquitectura de un Data Lakehouse
Desde el punto de vista de la arquitectura Cloud en la que implementar un Data Lakehouse se requieren los siguientes componentes:
- Sistema de almacenamiento: Azure Data Lake Gen2, Amazon S3, Google Cloud Storage etc.
- Recurso de cómputo para ejecutar las distintas ETLs que procesen y transformen los datos: clúster en Databricks, Synapse Engineering, jobs de AWS Glue, Google Dataproc, etc.
- Motor SQL para realizar consultas analíticas sobre los datos. Para ello se pueden usar recursos como Trino o Presto, AWS Athena, Azure Synapse, Databricks SQL o Google BigQuery.
En la siguiente figura se muestra un ejemplo concreto de arquitectura en el que se utiliza la plataforma Databricks sobre la nube de Azure, pudiendo ser extrapolable a otros proveedores cloud:
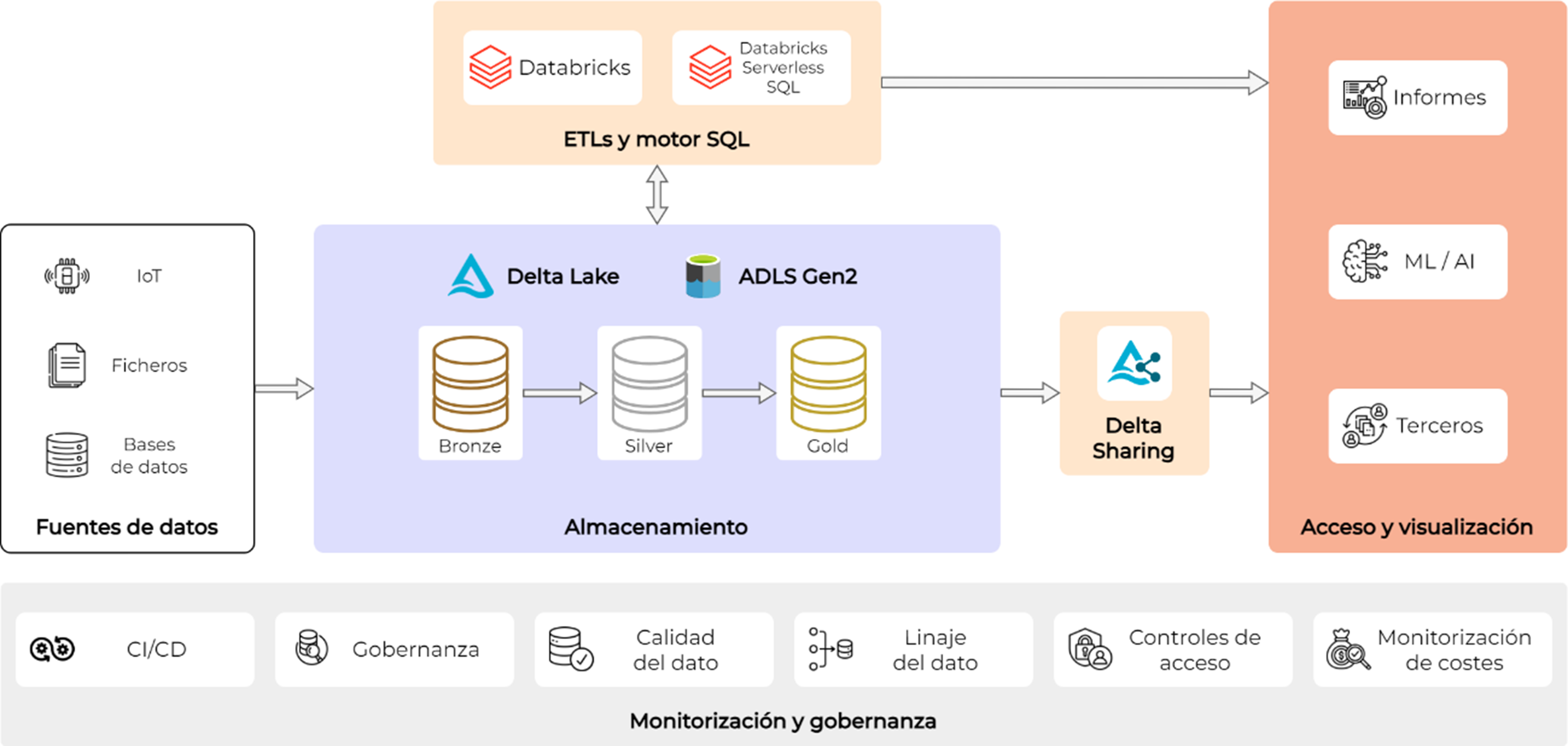
Arquitectura de datos
En cuanto al almacenamiento, Data Lakehouse utiliza formatos de datos compatibles con transacciones tales como Apache Hudi, Apache Iceberg o Delta Lake. En nuestra experiencia la opción que mejor se ajusta a la mayoría de las necesidades es Delta Lake debido a su compatibilidad con los otros formatos.
Delta Lake es una capa de almacenamiento optimizada y de código abierto que extiende el formato de los archivos Parquet añadiendo un registro con las operaciones realizadas. Esto le permite combinar las ventajas de los ficheros Parquet: particionamiento, almacenamiento columnar y compresión; con la fiabilidad de disponer de un sistema transaccional. Las características más destacables de Delta Lake son las siguientes:
- Evolución de esquema: soporta variaciones en el esquema de los datos. Esto añade una mayor flexibilidad al acomodarse a las nuevas circunstancias del dato sin la necesidad de tener que reescribirlos.
- Soporte de transacciones: Delta Lake almacena un registro con cada operación realizada sobre los datos. Esto garantiza que siempre se consultará una versión consistente de los datos, incluso si se están realizando modificaciones simultáneamente. En otras palabras, el sistema asegura el cumplimiento de las propiedades ACID (atomicidad, coherencia, aislamiento y durabilidad).
- Control de versiones: El registro de las operaciones permite la recuperación de estados previos en el caso de errores o problemas.
Para el esquema de almacenamiento se utiliza la arquitectura de medalla (la cuál explicaremos en profundidad en otro artículo). Este patrón de diseño de datos simplifica la lógica de gestión, mejorando la estructura y la calidad de los datos según van pasando por las diferentes etapas de procesamiento de la información: bronze, silver y gold.

Conclusiones
A lo largo de este artículo se han descrito las características y ventajas de este nuevo paradigma para la gestión y procesamiento de datos. Este enfoque permite a las organizaciones centralizar sus datos al añadir un sistema transversal a todas sus áreas.
Desde el equipo de Data Engineering de Decide apostamos por esta arquitectura, además de tener experiencia implementándola en distintos clientes. Ofrecemos una solución de Data Lakehouse sobre Databricks con un bajo tiempo de implantación, fácil mantenimiento, y gestión de acceso a la información de forma segura. Por otra parte, nuestra propuesta incluye todas las características necesarias para un desarrollo de código ágil y escalable disponiendo de Infraestructura como Código y CI/CD.
En cuanto a la explotación de los datos, enfocamos la arquitectura en proporcionar valor a todas las partes de la organización, tanto a nivel interno: Data Scientists, Business Intelligence, Reporting; como a nivel externo, facilitando la compartición segura de datos con terceros en el caso de que se requiera.
Todo ello complementado con un análisis previo de los requisitos, ajustando el coste de la solución a las necesidades de la organización.
Referencias
- https://cassio-bolba.medium.com/data-warehouse-vs-data-lake-vs-data-lakehouse-know-the-differences-51bb3f82e137
- https://www.databricks.com/glossary/data-lakehouse
- https://www.ibm.com/topics/data-lakehouse
- Delta Lake: The Definitive Guide Modern Data Lakehouse Architectures with Data Lakes Book
- Rise of the Data Lakehouse. Building the Data Lakehouse 2nd Edition – Bill Inmon.


