
En un artículo anterior se explicaba de forma divulgativa la matemática que hay detrás de un proyecto de mantenimiento predictivo. Este artículo pretende ilustrar un problema concreto: la detección de anomalías en molinos de viento.
Funcionamiento de un molino
Un molino de viento es una máquina que utiliza la energía del viento para diferentes tareas, en el caso que vamos a estudiar generar electricidad. Esta energía proviene de la acción de la fuerza del viento sobre unas aspas o palas unidas a un eje común. La fuerza del viento hace que las palas se muevan y accionen un generador eléctrico, que convierte la energía mecánica de rotación en energía eléctrica. Esta electricidad se puede almacenar en baterías o enviar directamente a la red.
En la actualidad, los molinos de viento funcionan mediante sensores y chips que en base a distintas mediciones controlan el funcionamiento del molino. Estos sensores también envían constantemente información del estado de cada uno de sus componentes. Lo que hace que sean los candidatos perfectos para llevar a cabo un estudio predictivo sobre ellos.
Partes de un molino
Una de las claves principales para el éxito de un proyecto es tener un fuerte conocimiento funcional sobre el tema que se está estudiando. En este caso, conocer cuáles son las piezas que componen el molino y cómo se conectan entre sí es esencial para poder entender los datos sobre los que vamos a trabajar.

No quiero inmiscuirme en el detalle y la funcionalidad de cada una de las piezas, pero sí me gustaría dar una descripción general de cómo funciona. El rotor está formado por las tres palas y la pieza que las une (buje). Cuando giran hacen girar también el «eje de baja velocidad» (low speed shaft) que gira a la velocidad de las palas. El multiplicador (Gear-box) se encarga de transformar la velocidad de giro a unas 1000 – 1800 rpm, velocidad necesaria para que el generador pueda producir electricidad. El pitch (cambia la inclinación de las hojas para controlar la velocidad del rotor), el freno (para el rotor en emergencias) o el controlador (enciende o apaga el molino dependiendo de la velocidad del viento) forman parte del sistema automático de control del molino.
Detección de anomalías en molinos de viento
Una anomalía se define como un patrón que está «fuera de lo normal». Una primera aproximación entonces puede ser definir una región que represente el comportamiento normal y considerar todo lo que esté fuera como anómalo. La definición de la «región normal» no es algo fácil. En este estudio usaremos una técnica de clusterización para definir la «región normal» y después una técnica de clasificación para poder automatizar la detección de anomalías en molinos de viento.
Datos de entrada
Los molinos que vamos a estudiar pertenecen al mismo parque eólico. De esta forma, nos podemos abstraer de los sensores que miden factores ambientales ya que van a ser iguales a todos los molinos. Partimos de los datos provenientes de las mediciones de los sensores de 4 molinos durante un año. Las mediciones se realizan cada 10 minutos así que partimos de un dataset de 210.816 columnas y 50 variables (sensores). Llamaremos medición a los datos pertenecientes a una fila de nuestro dataset, es decir a las medidas de todos los sensores para un molino en un instante determinado.
En una primera aproximación funcional dividimos las variables en tres tipos:
- Factores de entrada al molino: viento, temperatura, … son condiciones de entrada al molino. Son factores que influyen en la velocidad de las palas, y por tanto en el comportamiento de todos los componentes internos del molino. En este caso, y ya que todos los molinos pertenecen al mismo parque eólico podemos sacar estos datos del análisis, y tener en cuenta únicamente como dato de entrada la velocidad del rotor.
- Factores internos: son aquellas variables que indican el comportamiento de las piezas internas. Son en las que vamos a centrar el estudio de la detección de anomalías en molinos de viento.
- Factores de salida: son aquellas que indican la potencia y factores que influyen en cómo va a salir la energía del molino.
- Factores descartados: son aquellas variables que en un principio sacamos del análisis, porque funcionalmente no encontramos que tengan relación con las anomalías.
Vamos a centrar el estudio de momento en los «factores internos», ampliando luego a más variables si no encontramos en ellos ninguna conclusión por la que podamos considerar un dato anómalo.
De esta forma nos quedamos con las variables que miden factores que afectan al comportamiento interno del molino. Un total de 11 que miden la temperatura de los motores de pitch («Temp. Motor A1«, «Temp. Motor A2«,»Temp. Motor A3«), la oscilación de las aspas ( «Tower oscill. x «, «Tower oscill. y«,»Drive train osc. z«), temperatura de los cojinetes de la caja multiplicadora («Temp.gearb.bear.1«, «Temp.gearb.bear.2«, temperatura de los cojinetes del generador («Temp. gen.bearing1«, «Temp. gen.bearing2«), velocidad de salida de la caja multiplicadora («Gearbox speed«), temperatura del cojinete del rotor («Temp. rotor bearing«) y la velocidad del rotor («Rotor speed«).
Análisis descriptivo
Veamos gráficamente los datos de los sensores. Para hacernos una idea de cómo están distribuidos estos datos vamos a representar cada variable con un diagrama de cajas. Ilustro sólo dos para que sea más claro:
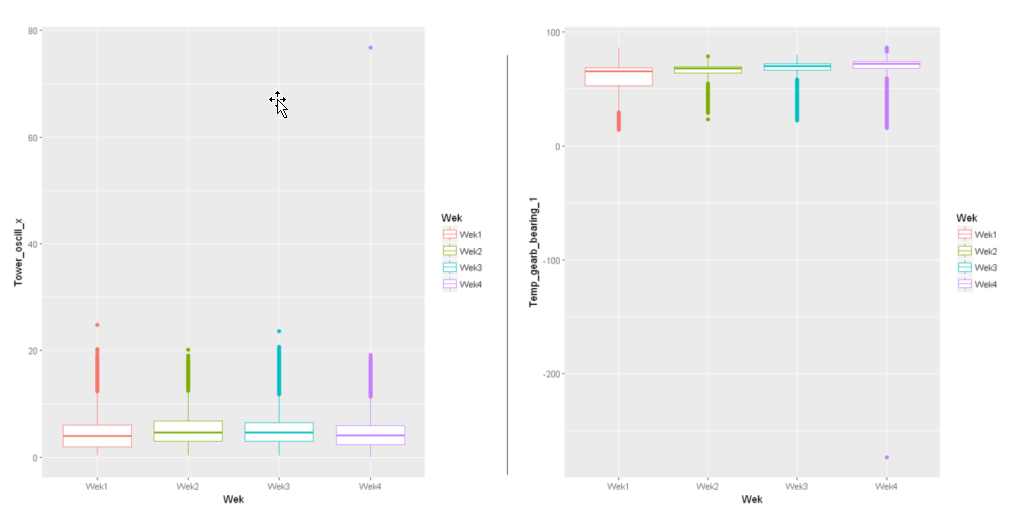
Tanto en estos como en los diagramas de cajas de otros sensores llama la atención un dato que está muy alejado de la caja en el molino 4 (simbolizado con color morado). Verificamos en los datos estos puntos tan alejados. En todos ellos la velocidad del rotor es 0, es decir que son los datos que graban los sensores cuando no están activados. Decidimos eliminarlos del conjunto de datos para que no interfieran en nuestro análisis.
También podemos ver que en el diagrama de cajas aparecen datos marcados como valores atípicos (serían los puntos más gruesos que están por encima o debajo de la caja). En principio no vamos a considerar anomalías de un solo sensor, a no ser que su valor esté muy alejado del valor central de la muestra ya que las piezas de un molino están conectadas y por tanto buscamos lo que se denominan «anomalías contextuales». Esto significa que el hecho de que la temperatura del cojinete de la caja multiplicadora sea «alta» no me dice nada por sí misma ya que puede ser que la velocidad de las palas sea alta también o que haga mucho calor, y por tanto el resto de las temperaturas medidas por los sensores sean altas también.
El siguiente gráfico de calor sobre la matriz de correlaciones (amarillo: variables no correladas, rojo: variables altamente correladas) nos verifica que el valor dado por un número considerable de sensores de los distintos componentes del molino están altamente correlacionados.

Clusterización
De cara a dislucidar qué se consideran datos normales o no, vamos a aplicar una técnica de agrupación llamada k-means. K-means es un algoritmo que va agrupando los datos de forma iterativa basándose en la distancia del dato al centroide del grupo o clúster. El número de clústeres (k) es un parámetro de entrada al algoritmo. Probamos con k entre 2 y 15. Para ver qué número de clusters separa mejor usamos el índice de Silhouette. Silhouette mide la sumilitud de un elemento con su cluster (cohesión) comparado con otros clústeres (separación) y toma valores entre -1 y 1, indicando los valores próximos a 1 una mejor agrupación.

En la imagen, el gráfico («K-means») relaciona el número de clústers k con el índice de silhouette que da la agrupación con k clústers. Deducimos que el número óptimo de clústeres es dos, con un índice de silhouette cercano al 0.8, que indica que los dos grupos hallados están bien identificados. El gráfico «Agrupación k=2» dibuja los dos clústeres mostrándonos gráficamente que están bien diferenciados.
Si nos fijamos en sus centroides, vemos que el «clúster 1» se identifica con las mediciones de los sensores cuando la velocidad de giro del rotor es alta (13.1 rpm) y agrupa la mayoría de datos (180.148 observaciones) mientras que el «clúster 2» contiene las mediciones cuando la velocidad es baja (0.8 rpm) agrupando tan sólo tiene 29.731.

Consideraremos datos anómalos aquellos que disten «anormalmente» del centroide de su clúster. Así pues, para cada medición hallamos la distancia al centroide del clúster al que pertenece, obteniendo el vector de distancias para el «clúster 1» y «clúster 2» repectivamente. Pintando dichos vectores en un diagrama de cajas podemos observar que no hay distancias muy alejadas del centroide en comparación con el resto, no encontrando evidencia estadística de que existan datos anómalos. No obstante, se debe consultar con los expertos en mantenimiento si cada punto identificado como outlier (los puntos más gruesos del gráfico) son datos anómalos. En el caso en el que los expertos clasifiquen algunos de ellos como anómalos e identifiquen por qué podremos empezar a sacar «reglas» que identifiquen nuevos datos como anómalos.
Aprendizaje Supervisado
En la clusterización no se ha encontrado ninguna evidencia estadística de que haya datos anómalos. Si los expertos en mantenimiento concluyen que no existen datos anómalos en los outliers nos encontramos con un conjunto de datos que no presenta anomalías. ¿qué hemos sacado entonces de la clusterización? Básicamente la definición de lo que se considera «normal». Esta definición deberá ser consensuada con el equipo de mantenimiento. En nuestro caso definimos datos normales como todos los datos que pertenecen al «cluster 1» y que distan menos de 850 y todos los datos que pertenecen al «cluster 2″ y distan menos de 800».
De cara a poder identificar futuras anomalías en molinos de viento, podemos usar técnicas de clasificación que clasifiquen los nuevos datos en «cluster1» y «cluster2». Aquellos datos clasificados como «cluster1» o «cluster2» que disten del centroide más de las distancias indicadas los identificaremos como posibles anomalías. Vamos a probar las siguientes técnicas de modelización:
- Discrimintante lineal (LDA): el discriminante lineal busca la combinación lineal de variables que mejor separan dos o más clases de objetos. Dado que el proceso de agrupación ha diferenciado con un silhouette alto los dos clústers parece que tiene sentido buscar un hiperplano que los separe.
- Modelos lineales generalizados (glmnet): generalización de la regresión lineal, que unifica varios modelos estadísticos incluyendo la regresión lineal, regresión logística y regresión de Poisson. Básicamente relaciona la distribución de la variable respuesta (en este caso el clúster) con las variables explicativas (los sensores) a través de una función llamada «función de enlace» .
- Máquinas de vector soporte (SVM): Buscan también un hiperplano que separe las dos clases haciendo si es necesario una previa conversión del espacio (mediante una función denominada kernel) en los casos en los que las clases no sean linealmente separables.
Un modelo necesita ser evaluado en datos con los que no hayan sido usados para prepararlo para evitar el sobre-ajuste. De esta forma, se usan un subconjunto de los datos llamado datos de entrenamiento para ajustar el modelo y se mide su precisión en el subconjunto complementario llamado datos de test. En nuestro caso hemos decidido usar una técnica de validación cruzadada. Esta técnica divide los datos en k subconjuntos. El modelo se entrena con k-1 de ellos y se evalúa en el restante. Este proceso es repetido hasta que todos los subconjuntos han servido para entrenar y evaluar en alguna de las repeticiones. La precisión final viene dada por la media de las precisiones de cada repetición. El resultado en nuestro caso es el siguiente:
Como vemos, todos los modelos ajustan bastante bien, aún así nos quedamos con la máquina de vector soporte que es la que más precisión nos da. La razón de que todos los modelos den una precisión tan alta es que los clústeres estaban bien diferenciados, haciendo que los datos se puedan clasificar fácilmente

Según se vayan clasificando datos en los clústeres habrá que ir actualizando su centroide, para poder seguir considerando éste como el centro del clúster. Además, cada cierto tiempo habrá que volver a formar los clústeres con datos nuevos aplicando de nuevo una técnica de agrupación, por si aparece algún patrón no indentificado anteriormente.
Resumen:
En este artículo hemos ilustrado la ejecución de un estudio de detección de anomalías en molinos de viento, estableciendo qué se considera una medición normal o no mediante una clusterización de los datos. El resultado ha sido dos grupos claramente diferenciados, uno que contiene las mediciones cuando la velocidad de las palas del molino es próxima a 0 r.p.m y otro cuando la velocidad de las palas del molino es próxima a 13 rpm. De la clusterización hemos deducido también que el conjunto de datos del que disponemos no contiene datos anómalos. En base a esto definimos datos normales como todos los datos que pertenecen al «clúster 1» y que distan menos de 800 y todos los datos que pertenecen al «clúster 2» y distan menos de 850. Estas distancias se han determinado de forma que dejan a todos los puntos del dataset en uno de los dos clústers y establecen un margen para identificar un dato cómo anómalo. Hemos aplicado después una técnica de clasificación para poder clasificar nuevas mediciones en uno de los dos grupos. Finalmente catalogaremos como anómalos aquellos datos que pertenezcan a un clúster y su distancia al centroide esté por encima de los límites establecidos.


