In recent years, many times I have had to argue that the using Linear and Integer Linear Programming was not the most appropriate one to solve routing problems. This is not an absolute truth, although it is true that it makes quite a bit of sense as a general rule.
In this article I will try to explain why I believe this, and prove it with an example. Let’s look at modelling the Travelling salesman problem which, although apparently simple, belongs to the category of NP-complete problems and which therefore has been subject to multiple attempts at finding a solution. We’ll see that, indeed, there is a theoretical way of solving this problem with one (or several) integer linear formulations, although we will also see that, in practice, in cases where performance is more important than optimality, this method is not the most appropriate.
For those not familiar with it, the Travelling salesman problem is very easy to describe: If we have N destinations to visit, the objective is to find the shortest route for visiting the N destinations. Normally it is assumed that you start and end in the same destination, although this is not important.
Assuming you have to visit the following destinations:

You have to find a route for all the destinations, which, probably, would look something like this:

Problem Formulation
Next I will introduce the standard formulation for this problem using an Integer Linear approach. Let’s say you have:
- D: Set of all destinations
- Xij: Binary variable that indicates whether your travel the trail that goes from destination i to destination j.
- dij: Constant that shows distance between destinations i and j.
A valid formulation would be the following (although there are more compact formulations, I think this one is clearer):

That is:
- A target function that minimises the distance travelled.
- A set of restrictions (entry) that guarantee entering each destination once.
- A set of restrictions (exit) that guarantee exiting each destination once.
- A set of restrictions (subtour) that guarantee the path is unique.
I think it is worth understanding now why it is necessary to define (subtour) type restrictions. If these restrictions were not present, we would get a solution like this one:

At a glance, this solution meets all the restrictions of the formulation proposed except for the (subtour). That is, you exit and enter each destination only once, and it is much better for the target function than the previous solution (you travel a shorter distance). Type restrictions (subtour) guarantee precisely that, for each subset of destinations S with more than one element and different from total (D), the number of trails arising from this subset is at least one, avoiding the subpaths that invalidate the solution.
The problem here is that, if the set of destinations (D) is big enough, its number of possible subsets (S) is enormous, so the model, which has a type restriction (subtour) for each one of them, grows until it is intractable. In fact, the number of subsets of D is 2^|D|, that is, it grows exponentially as D increases.
A rather common approach used to overcome this problem is precisely to solve a series of sub-problems that incorporate type restrictions (subtour) as necessary. Let’s assume you start with a model without type restrictions (subtour), the algorithm would look like this:
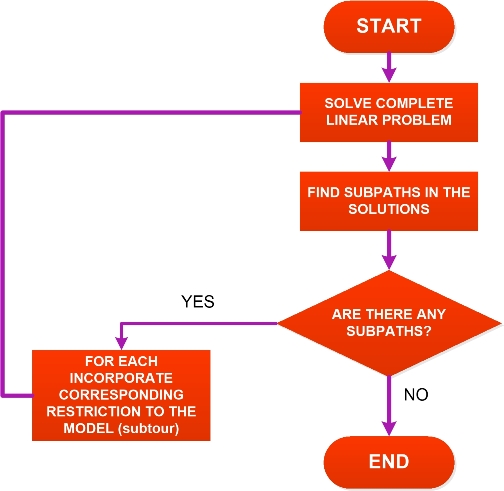
This way, the moment the algorithm ends, you’ll have an optimal solution with no subpaths. Also, you’ll be certain that the algorithm ends, since, in the worst case, it would end up adding all the type restrictions (subtour), which are finite, therefore it has to end.
Conclusions
At first glance, this algorithm might seem acceptable and, in fact, in some cases it is. But usually, for medium-sized problems, the number of iterations of the algorithm until an optimal solution without subpaths is found can be very high, leading to wait times that are not acceptable for the industry.
Also, this method has an additional problem when applied to real problems (that is, to problems where a user expects to find a solution which is necessary to continue working): the algorithm does not generate a valid solution until it ends. It is important to understand this. All the solutions found after each iteration (except the last one) are somehow optimal, but not feasible, since they have subpaths. This, which may not be a problem in the academic world, where you can leave a supercomputer processing for days to solve an unsolved TSPLIB instance, is unacceptable when solving a real problem.
Imagine a user that, after waiting for an hour in front of his screen to find a solution for his problem, decides to stop running it and keep the best solution up to that moment. When he sees it, he realises the solution is very good with respect to the distance travelled, but it is no good, as it is not really a solution to his problem: he was looking for a single path and he has a solution comprising several subpaths.
In business, it is more important to have a good solution in a short period of time than the best solution in hours or days. This is precisely why, to solve routing problems, it is more common to use Metaheuristic algorithms which may not generally guarantee solution optimality, but they do assure, at every moment, that there is a feasible solution to the problem, even if it is not the best one.



